Scaling JVM deployments on Kubernetes
Table of contents
- Introduction
- How to define CPU requests/limits to handle cold start?
- What metrics to use for scaling?
- Slow start for JVM application
- Quality of Service
Introduction
This post is about the complexity with scaling JVM apps on K8S.
The code for this post can be found at the blog repo.
A good scaling strategy is crucial when the traffic increases at your services, and it’s not straightforward to implement. At the very basic level you can have a HorizontalAutoScaler (HPA) scale up deployment with more replicas based on the resource utilization. In this post I will explain how to scale a Spring Boot app where we want to minimize latency spikes.
I choose Spring Boot in particular because it’s running on the JVM and therefore inhibits some special properties:
- Requires lots of CPU at cold start
- The JVM requires a warm-up period before being able to respond to requests with optimal performance
How to define CPU requests/limits to handle cold start?
There are three options for defining CPU resources:
- Set
requests.cputo less thancpu.limits
requests:
cpu: 200m
limits:
cpu: 1000m
- Set only
requests.cpuand skipcpu.limits
requests:
cpu: 200m
- Set
requests.cputo the same aslimits.cpu
requests:
cpu: 200m
limits:
cpu: 200m
The reasoning for option #1 is that requests.cpu is set to a baseline where the app will function well under normal
load and allow it to use more CPU up to the limit during start and under high load. A limit is set to avoid being the
noisy neighbour and leave CPU to other processes on the node.
From the application developers perspective, option #2 is a great alternative since it allows the app to use any excess CPU available without being limited. Excess CPU resources are distributed based on the amount of CPU requested1. However, the platform operator might not be comfortable with containers running without limits since they might not be well-behaved.
Both option #1 and #2 suffer from a hidden problem that will occur when the node is under high load. The app might not be able to claim more CPU when needed if the underlying node doesn’t have any excess CPU. This will also be a problem when scaling based on CPU limits since the app will might never reach the needed amount of CPU usage the to trigger the HPA.
If we can find a number to use for both requests.cpu and limits.cpu that satisfies our time requirement for booting
from cold start it is a viable middle-ground. The behaviour will be much more predictable since the app will operate
under the same conditions at all times.
What metrics to use for scaling?
As always, it depends on the nature of your application. Using CPU based scaling generally works pretty well, but you might want to really think of the implications when using the standard HPA CPU Utilization:
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
When using the sidecar pattern this might not be optimal unless you have fined-tuned the CPU resources for all containers. 2
Note: Since the resource usages of all the containers are summed up the total pod utilization may not accurately represent the individual container resource usage. This could lead to situations where a single container might be running with high usage and the HPA will not scale out because the overall pod usage is still within acceptable limits.
A better idea is to use Istio metrics to scale based on RPS. You want to find the point where the application can handle a certain RPS without having the latency turn significantly worse. The application should scale when the load is approaching this RPS per replica. This works best with non-sticky sessions of course and where the application can scale linearly. See more at this repo by Stefan Prodan.
Slow start for JVM application
When K8S scales out your application, it will need some warm up time before it is up and running at full speed. Istio supports warm up by progressively increase the amount of traffic for a new endpoint. 3
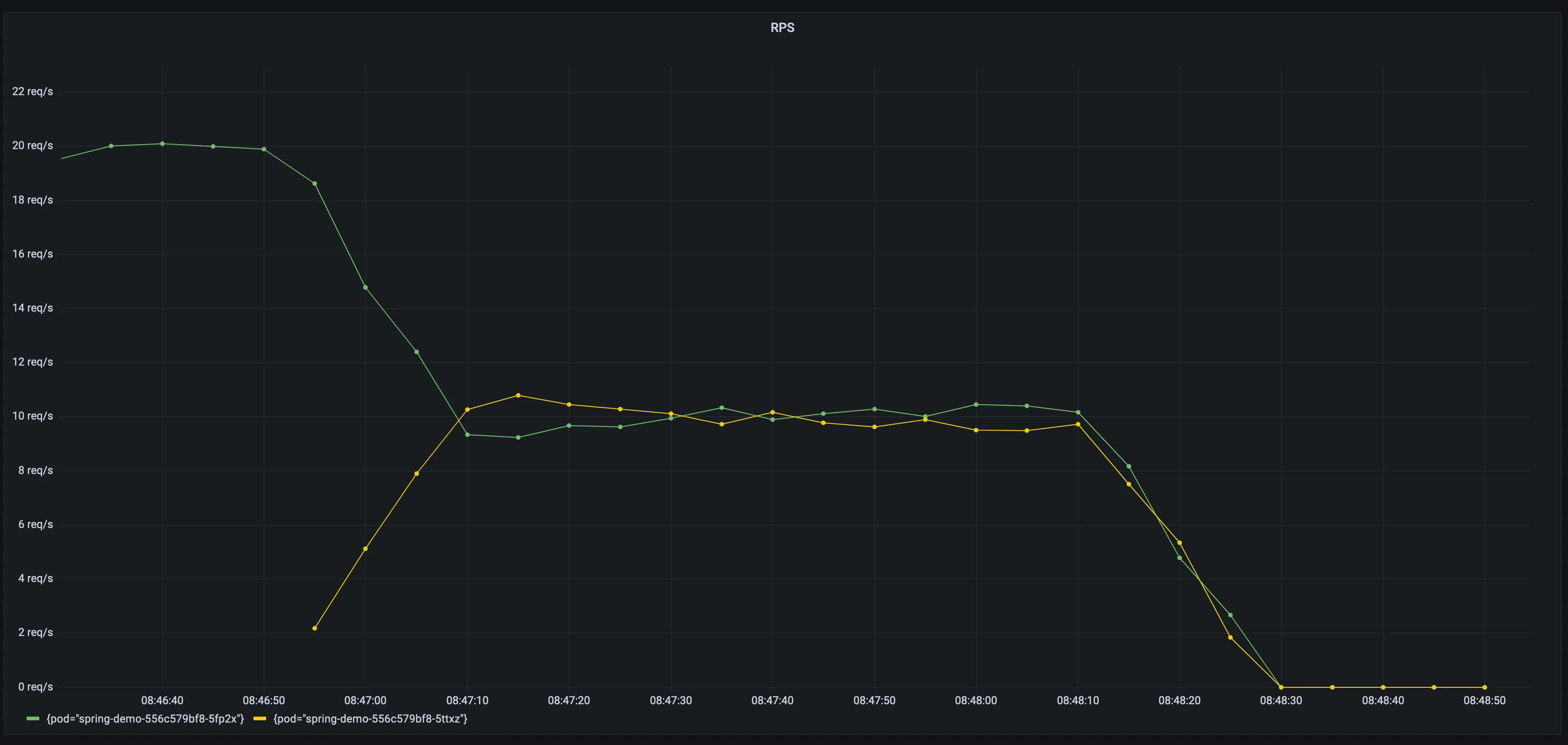
Load test without slow start
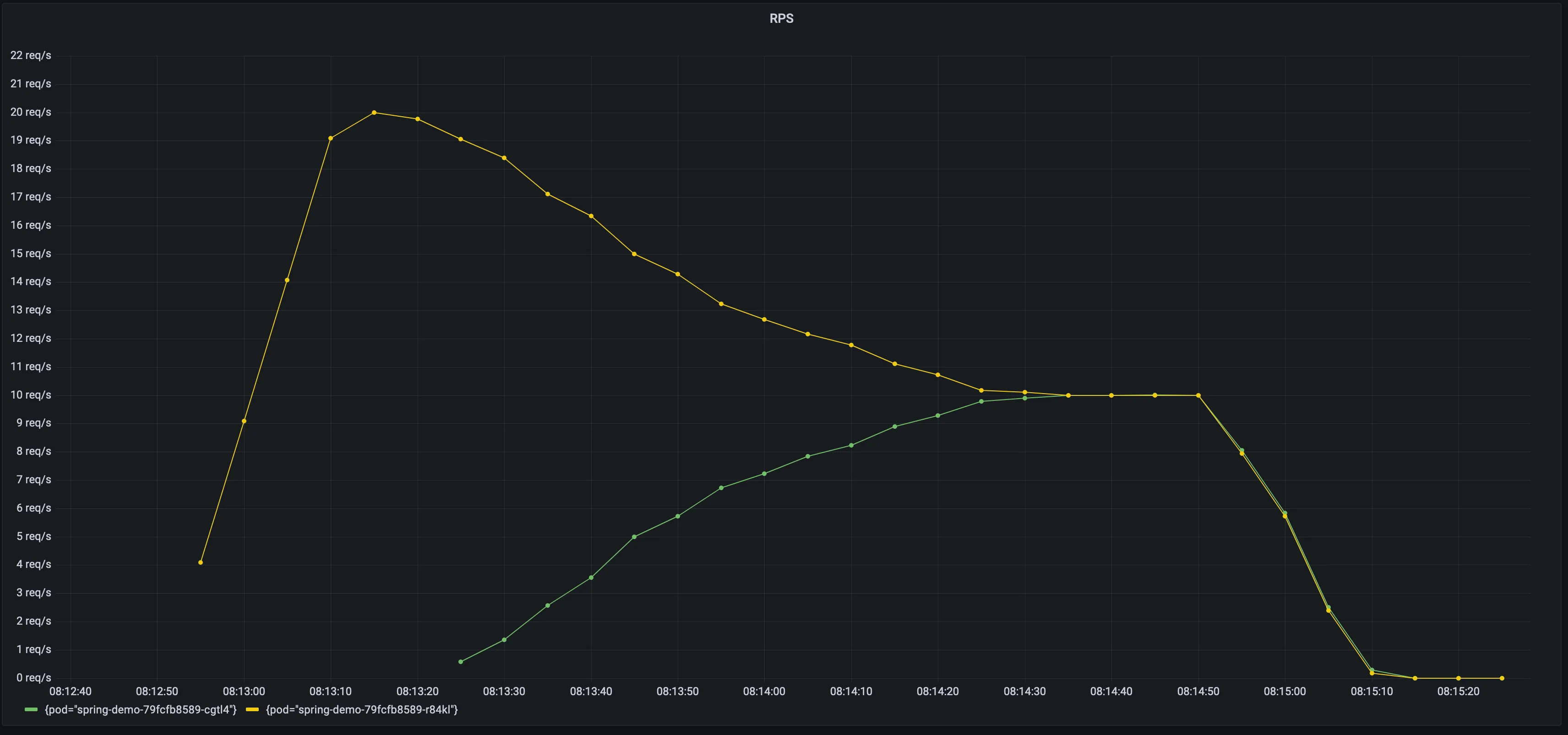
Load test with slow start
Quality of Service
An aspect I haven’t talked about is Quality of Service (QoS). There are three QoS classes in K8S4:
- Guaranteed
Pods are considered top-priority and are guaranteed to not be killed until they exceed their limits. 5
- Burstable
Pods have some form of minimal resource guarantee, but can use more resources when available. Under system memory pressure, these containers are more likely to be killed once they exceed their requests and no Best-Effort pods exist.5
- BestEffort
Pods will be treated as lowest priority. Processes in these pods are the first to get killed if the system runs out of memory. These containers can use any amount of free memory in the node though. 5
Using the options defined above then #1 and #2 will have a QoS of Burstable, while #3 will be Guaranteed.
Footnotes
-
https://github.com/kubernetes/design-proposals-archive/blob/main/node/resource-qos.md#compressible-resource-guarantees ↩
-
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-resource-metrics ↩
-
https://istio.io/latest/docs/reference/config/networking/destination-rule/#LoadBalancerSettings ↩
-
https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/ ↩
-
https://medium.com/google-cloud/quality-of-service-class-qos-in-kubernetes-bb76a89eb2c6 ↩ ↩2 ↩3